
近年AIが進化する中でよく聞く言葉の一つに「LLM:大規模言語モデル」があります。
LLMとはどういうものなのでしょうか?
そこで今回は、LLMの仕組みと活用方法について初心者でも分かりやすいように解説します。
また、難しい専門用語については、記事の中でわかりやすく説明します。
当記事は、2025年3月時点の最新情報でまとめています。
AIの急速な発展

ここ数年間でAI技術は驚異的な速度で進化しています。
特に2020年以降、大規模言語モデル(LLM)の発展により、AIは私たちの日常生活やビジネスに大きな変革をもたらしています。
わずか数年前までは、文章を理解し人間らしい応答を返すAIは、SF映画の中の存在でした。
しかし今や、ChatGPTやClaudeといったAIアシスタントは数億人のユーザーが日常的に利用するサービスとなりました。
このAI革命は単なるテクノロジーの進化にとどまらず、私たちの働き方や情報との関わり方を根本から変えつつあります。
プログラマーからマーケター、クリエイターまで、あらゆる職種の人々がLLMを活用して生産性を向上させています。
では、この革命の中心にある「LLM」とは一体何なのでしょうか?
LLMとは何か?

LLM(Large Language Model:大規模言語モデル)とは、膨大な量のテキストデータを学習して言語を理解・生成できる人工知能モデルです。
「大規模」という名前の通り、これらのモデルは数千億から数兆のパラメータ(モデル内の調整可能な値)を持ち、インターネット上の膨大なテキストデータで学習されています。
LLMの基本的な仕組みは以下の通りです。
- 事前学習:インターネット上の膨大なテキストデータから言語の規則やパターン、事実知識などを学習します。
- パターン認識:文章の続きを予測するタスクを通じて、言語の構造や意味を理解します。
- 文脈理解:前後の文脈から適切な応答を生成する能力を身につけます。
LLMの特徴的な点は、特定のタスク向けに設計されたAIとは異なり、汎用的な言語理解能力を持っていることです。
同じモデルで文章生成、翻訳、要約、質問応答など、様々なタスクをこなすことができます。
最新のLLMは、単なる文章の生成を超え、論理的思考や複雑な問題解決、創造的な作業までこなせるようになっています。
これは、モデルサイズの拡大だけでなく、人間からのフィードバック学習(RLHF:Reinforcement Learning from Human Feedback)など、新しい学習手法の導入によるものです。
最新LLMの特徴
2025年3月現在の最新LLMは、数年前のモデルと比較して飛躍的に性能が向上しています。
主な特徴は以下の通りです。
1. 高度な推論能力
最新のLLMは単純な文章生成を超え、複雑な推論や問題解決能力を持ちます。
数学的問題の解決、論理パズルの解明、事実関係の分析など、高度な思考プロセスを必要とするタスクでも優れた性能を発揮します。
例えば、Claude 3.7やGPT-5では、「思考連鎖」(Chain of Thought)と呼ばれる方法でステップバイステップの推論過程を示すことができ、より透明性の高い回答を提供します。
2. 長期記憶と文脈理解
初期のLLMでは、一度の会話で扱える文脈(コンテキストウィンドウ)が限られていました。
しかし、最新モデルでは数十万トークン(単語や文字の単位)に拡張されています。
これにより、長い文書や複雑な会話の流れを維持したまま応答が可能になりました。
また、会話履歴を保存する機能も進化し、以前の対話を覚えていることで、一貫性のあるサポートが可能になっています。
3. マルチモーダル能力
テキストだけでなく、画像、音声、動画などの複数のモダリティ(情報形式)を理解・処理できる能力を持ちます。
例えば、ユーザーが画像をアップロードすると、その内容を詳細に分析し、テキストで説明したり、画像に基づいた質問に答えたりできます。
これにより、「この写真のエラーメッセージの原因は?」「この図表のデータ傾向を分析して」といった複合的なタスクが可能になっています。
4. 専門知識の深化
最新のLLMはより専門的な領域での知識が豊富になっています。
法律、医学、プログラミング、金融など、特定の分野に特化したモデルも増えており、専門家レベルのアドバイスや支援が可能になっています。
例えば、プログラミングに特化したモデルではコードの生成だけでなく、デバッグや最適化の提案まで行えるようになっています。
最新LLMの機能

現代のLLMが提供する主要機能を見ていきましょう。
1. コンテンツ生成
最も基本的な機能はテキスト生成です。
ブログ記事、メール、レポート、詩、物語など、様々な形式の文章を作成できます。
ユーザーの指示に基づいて、トーンや長さ、スタイルを調整したコンテンツを生成します。
特に最新モデルでは、「一貫性のある長文」「目的に合わせた構造化された文書」など、より複雑で質の高いコンテンツ生成が可能になっています。
2. データ分析と要約
大量のテキストデータを分析し、重要なポイントを抽出して要約する機能があります。
長い記事、研究論文、会議の議事録などを、核心を保ちながらコンパクトにまとめることができます。
また、複数の情報源からデータを統合し、傾向や洞察を導き出すことも可能です。
3. 対話とアシスタント機能
自然な会話を通じてユーザーの質問に答え、タスクを支援します。
単なる情報提供を超え、問題解決のガイド、アイデアのブレインストーミング、学習のサポートなど、様々な形でアシスタントとして機能します。
2025年の最新モデルでは、ユーザーの意図をより正確に理解し、必要に応じて質問を重ねながら、より適切なサポートを提供できるようになっています。
4. コード生成と技術サポート
プログラミング言語を理解し、ユーザーの要件に基づいてコードを生成します。
また、既存のコードの説明、デバッグ、最適化の提案なども行います。
2025年の最新モデルでは、単純なスクリプトだけでなく、複雑なアプリケーションの設計や、特定の技術スタックに最適化されたコード生成も可能になっています。
5. パーソナライゼーション
ユーザーとの対話を通じて学習し、個々のニーズや好みに合わせた応答を提供します。
使用頻度が高まるほど、ユーザーの文体や関心事を理解し、より適切なサポートが可能になります。
最新モデルでは、ユーザーのコンテキストを維持する能力が向上し、長期間にわたる一貫したサポートを提供できます。
生成AIとLLMの違い

「生成AI」と「LLM」という用語は時々混同されることがありますが、正確には以下のような関係があります。
生成AI(Generative AI)
- より広い概念で、「新しいコンテンツを創造するAI」全般を指します
- テキスト、画像、音楽、動画など、あらゆる種類のコンテンツを生成可能
- 代表例:DALL-E(画像)、Midjourney(画像)、Sora(動画)、LLMなど
LLM(Large Language Model)
- 生成AIの一種で、特に「言語・テキスト」に特化したモデル
- 主にテキストデータの理解と生成に焦点
- 代表例:GPT-4、Claude、Llama 3、Gemini Advanced、PaLM 2など
つまり、LLMは生成AIの一部であり、テキスト処理に特化したモデルと言えます。
マルチモーダルLLM(テキストだけでなく画像なども理解できるモデル)の登場により、境界線は少し曖昧になってきていますが、基本的にはテキスト処理がLLMの中核機能です。
LLMの特徴は、何百億もの文章から学習した「言語理解」と「文脈把握」能力にあります。
一方、DALL-EのようなAIは視覚的な創造性に特化しており、それぞれ得意分野が異なります。
代表的なLLMの比較
2025年現在、主要なLLMには以下のようなものがあります。それぞれの特徴を比較してみましょう。
1. GPT-5(OpenAI)
- 強み: 高度な推論能力、創造的なコンテンツ生成、プログラミング支援
- 特徴: プラグイン連携による機能拡張、API経由での柔軟な利用
- 利用シーン: 企業向けカスタマーサポート、コンテンツ制作、研究支援
2. Claude 3.7 Sonnet(Anthropic)
- 強み: 論理的な思考能力、長文理解、倫理的な回答
- 特徴: 長いコンテキストウィンドウ、詳細な推論過程の説明
- 利用シーン: 論文や法律文書の分析、コンプライアンス対応
3. Gemini Advanced(Google)
- 強み: 情報検索との連携、マルチモーダル能力、最新情報へのアクセス
- 特徴: Google検索と連携した最新情報の提供、複数メディアの統合理解
- 利用シーン: 最新情報を必要とする質問応答、画像と文章を組み合わせた分析
4. Llama 3 401B(Meta)
- 強み: オープンソースでの展開、カスタマイズ性、低リソース環境での実行
- 特徴: 自社サーバーでのホスティング可能、セキュリティ重視の設計
- 利用シーン: プライバシー要件の厳しい企業での利用、エッジデバイスでの実行
5. 国産LLM(例:NTT系「tsuzumi」)
- 強み: 日本語処理の最適化、国内法規制への対応、日本文化コンテキストの理解
- 特徴: 日本企業向けユースケースの豊富さ、国内データセンター利用
- 利用シーン: 日本市場特化型サービス、行政・公共サービスでの活用
モデル選択のポイントは、必要な機能、セキュリティ要件、コスト、特定言語(日本語など)のサポート品質によって異なります。
2025年においては、単一モデルに依存するよりも、用途に応じて複数のモデルを使い分ける「マルチLLM戦略」が主流になっています。
最新LLMの活用事例

LLMは様々な産業で革新的な活用がされています。いくつかの代表的な事例を見てみましょう。
ビジネス分野での活用
- カスタマーサポートの強化
大手ECサイトでは、LLMを活用した24時間対応のカスタマーサポートシステムを導入し、問い合わせ対応時間を平均65%短縮しています。単純な質問には即座に回答し、複雑な問題は適切な担当者に引き継ぐインテリジェントな振り分けも行っています。 - 営業・マーケティング資料の自動生成
営業チームがLLMを活用して、顧客ごとにカスタマイズされた提案書や営業資料を短時間で作成。従来3日かかっていた提案書作成が数時間に短縮され、より多くの見込み客へのアプローチが可能になりました。 - 社内ナレッジベースの効率化
大量の社内文書、マニュアル、過去の問い合わせ履歴などをLLMに学習させ、社員がいつでも自然言語で質問できるシステムを構築。新入社員のオンボーディング時間が30%短縮され、ベテラン社員の知識継承も効率化されています。
クリエイティブ分野での活用
- コンテンツ制作の効率化
出版社やメディア企業では、LLMを「執筆アシスタント」として活用。記者が方向性や要点を指示すると、LLMが下書きを作成し、そこに記者が専門知識や独自の視点を加えるという協働スタイルが確立されています。 - 広告コピーのA/Bテスト効率化
広告代理店では、LLMを活用して数十パターンの広告コピーバリエーションを短時間で生成し、効果的なA/Bテストを実施。従来のクリエイティブプロセスと比較して、開発時間が75%短縮されたという報告があります。 - ゲームシナリオとNPC対話の強化
ゲーム開発会社では、LLMを活用してノンプレイヤーキャラクター(NPC)の対話システムを刷新。プレイヤーの行動や選択に応じて変化する自然な会話が可能になり、ゲーム体験の没入感が大幅に向上しました。
教育・研究分野での活用
- パーソナライズド学習支援
教育機関では学生一人ひとりの理解度や学習スタイルに合わせた教材をLLMで生成。同じ内容でも、視覚的に学ぶ生徒、ステップバイステップで学ぶ生徒など、学習者に最適化した説明方法を提供しています。 - 研究論文の分析と仮説生成
研究者がLLMを活用して、膨大な量の学術論文から関連情報を抽出し、新たな研究仮説を生成。特に学際的な研究において、異なる分野の知見を結びつける洞察を得るツールとして活用されています。 - 医療診断サポート
医療機関では、患者の症状や検査結果、医療記録をLLMに分析させ、診断候補や追加で必要な検査を医師に提案するシステムを試験導入。医師の最終判断を支援し、見落としを減らす補助ツールとして効果を上げています。
これらの事例から分かるように、LLMは単独で機能するというよりも、人間の専門知識や創造性と組み合わせることで最大の効果を発揮します。
最も成功している導入事例は、AIと人間それぞれの強みを活かした協働モデルを構築しているものです。
最新LLMの課題と今後の展望

LLMは革新的な技術ですが、いくつかの重要な課題も抱えています。その課題と今後の展望を見ていきましょう。
現在の主な課題
- 幻覚(ハルシネーション)の問題
LLMが実際には存在しない情報を自信を持って提示してしまう現象は、依然として重要な課題です。特に専門分野や最新情報について、誤った情報を生成するリスクがあります。 - バイアスと公平性
学習データに含まれる社会的バイアスが、AIの出力にも反映されることがあります。特定の集団に対する偏見や、ステレオタイプの強化が懸念されています。 - 透明性と説明可能性
LLMが複雑な判断をどのように行っているのか、その内部プロセスは完全には解明されていません。「ブラックボックス」的な性質が、特に重要な意思決定への活用を難しくしています。 - プライバシーとデータセキュリティ
LLMに入力されたデータの取り扱い、個人情報保護、企業秘密の漏洩リスクなど、セキュリティ面での懸念が存在します。 - 計算資源と環境負荷
最先端LLMの学習と運用には膨大な計算資源が必要であり、エネルギー消費や環境負荷の観点から持続可能性に疑問が投げかけられています。

今後の展望
- 特化型モデルの進化
汎用的なLLMに加え、特定の産業や用途に特化した小規模で効率的な特化型モデルの開発が進むと予想されます。医療、法律、金融などの専門分野で、より正確で信頼性の高いAIアシスタントが登場するでしょう。 - マルチモーダル能力の強化
テキストだけでなく、画像、音声、動画、3Dモデルなど、複数の情報形式を統合的に理解・処理できる能力がさらに向上すると見られています。現実世界の複雑な情報を包括的に理解するAIへと進化していくでしょう。 - エッジAIへの移行
クラウド依存型のLLMから、端末上で動作する軽量モデルの開発が進み、プライバシーやレイテンシの問題が解消されると期待されています。特にモバイルデバイスやIoT機器での活用が拡大するでしょう。 - 自律型エージェントの台頭
LLMを基盤とした自律型AIエージェントの開発が進み、より複雑なタスクを自発的に遂行できるシステムが登場すると予測されています。情報検索、分析、意思決定、実行までを一貫して行えるアシスタントへと進化するでしょう。 - 人間とAIの協働モデルの確立
LLMは人間の代替ではなく、人間の能力を拡張するツールとしての位置づけが明確になっていくでしょう。人間の創造性、倫理的判断、文脈理解とAIの処理能力、一貫性、知識量を組み合わせた新しい働き方が標準になると予想されます。
LLM技術は急速に進化していますが、これらの課題を解決しながら発展していくことで、より安全で効果的、そして人間中心のAIツールへと成熟していくことが期待されています。
マルチモーダルAI「Gemini」を使ってみた感想
Google製のマルチモーダルAI「Gemini」を実際に使用した体験を共有します。
Geminiは2023年末に発表され、2024年に大幅なアップデートを受けた最新のAIモデルです。
テキストだけでなく画像、音声、動画などの複数の情報形式を扱える「マルチモーダル」機能が特徴です。
使用体験の概要
私は約3週間、フリー版で使える、Gemini を日常的なタスクや仕事の一部で使用してみました。
2025年3月時点でGoogleは、以下の機能を無料ユーザーに解放しました。
- Gemini 2.0 Flash:日常的なタスクをサポート
- Gemini 2.0 Flash Thinking:高度な推論機能
- Gemini 2.0 Deep Rsearch:詳細な調査レポートを提供
- Gemini 2.0 Personalization:検索履歴に基づいてサポート
主に以下のような用途で活用しました。
- 画像を含む質問応答
- ドキュメントの分析と要約
- コーディング支援
- マーケティング素材の作成
印象的だった機能
画像理解能力
Geminiの画像理解能力は非常に印象的です。
例えば、エラーメッセージのスクリーンショットを送ると、そのエラーの原因と解決方法を詳しく説明してくれたり、知りたいことを画像から説明してくれました。
具体的には、意味不明なドメインがGoogleアナリティクスに表示されたので、キャプチャーしました。
画像に不明なURLの部分を矢印で示しました。
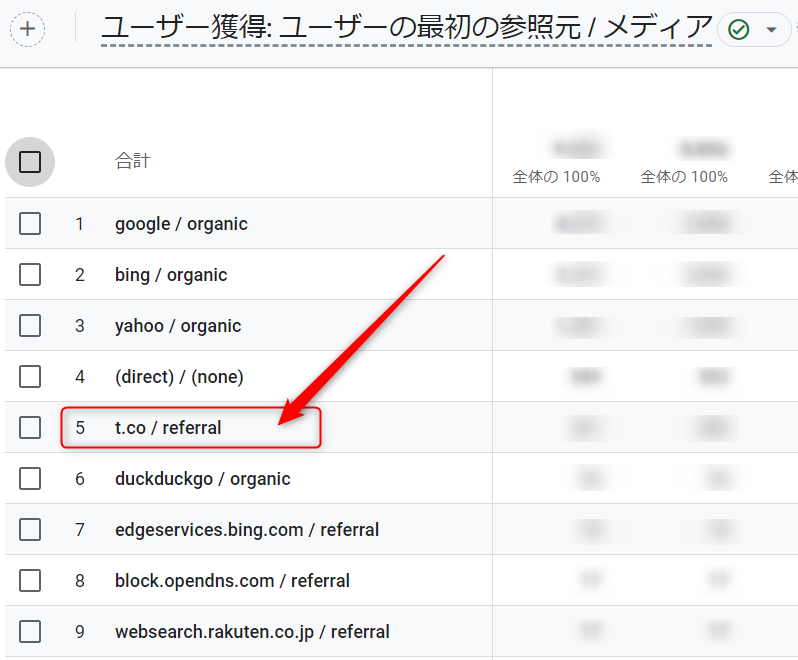
Geminiに以下の様に画像を添付して質問しました。

その結果、画像の中の矢印が示しているURLを読み取って、なにを意味しているのか、以下の通り回答しました。

これは、最近可能になったことです。
また、商品パッケージの写真から成分一覧を抽出し、アレルギー成分の有無を確認するといった複雑なタスクも正確にこなします。
特に図表やグラフの理解が優れており、データの傾向やポイントを的確に分析してくれる点が業務効率化に役立ちました。
Googleサービスとの連携
Google検索と連携している点は大きな強みです。
「2024年のSEOトレンド」のような最新情報を必要とする質問に対して、リアルタイムの検索結果を参照しながら回答してくれるため、情報の鮮度が高いと感じました。
また、Google DocsやSpreadsheetsとの連携機能も便利で、ドキュメント内容の分析や編集提案を直接行えます。
コーディング支援
プログラミング支援においても、Geminiは優れたパフォーマンスを発揮します。
特にPythonやJavaScriptのコード生成や修正において、コードの説明と共にベストプラクティスも提示してくれる点が学習にも役立ちました。
さらに、エラーメッセージのスクリーンショットを送ると、そのエラーの原因と解決方法を詳しく説明してくれる機能は、デバッグ時間の短縮に大いに役立ちました。
課題と感じた点
一方で、いくつかの課題も感じました。
- 長文理解の限界:非常に長いドキュメントを扱う場合、全体の一貫性を保った分析が難しいケースがありました。
- 専門分野での精度:一般的な内容では正確ですが、非常に専門的な分野(例:特定の法律条文の解釈)では、やや精度が落ちることがありました。
- 複雑な指示への対応:多段階の複雑な指示を一度に与えると、一部が実行されないことがありました。
他のAIと比較して
Claude 3.7やGPT-4と比較すると、Geminiは以下のような特徴がありました。
- マルチモーダル能力:画像理解においては、同等以上の性能を感じました
- 情報の鮮度:Google検索連携により、最新情報へのアクセスが優れています
- 使いやすさ:インターフェースがシンプルで直感的です
- レスポンス速度:特に軽量版の「Gemini Flash」は応答が非常に速いです
総合的に見て、Geminiは特に「検索と連携した最新情報の提供」「画像を含む複合的なタスク」において優れた選択肢だと感じました。日常的な業務や情報収集においては、検索連携の強みが大きく活きてくると思います。

まとめ
本記事では、LLM(大規模言語モデル)の基本から最新動向まで、初心者にも分かりやすく解説してきました。ここで重要なポイントを振り返りましょう。
- LLMの基本理解:LLMは膨大なテキストデータから学習し、人間のような言語理解・生成能力を持つAIモデルです。生成AIの一種であり、特にテキスト処理に特化しています。
- 最新モデルの特徴:2025年の最新LLMは、高度な推論能力、長期記憶、マルチモーダル能力、専門知識の深化など、飛躍的に進化した特徴を持っています。
- 主要な機能:コンテンツ生成、データ分析・要約、対話・アシスタント機能、コード生成・技術サポート、パーソナライゼーションなど、多様な機能を提供しています。
- 主要モデルの比較:GPT-5、Claude 3.7、Gemini Advanced、Llama 3、国産LLMなど、各モデルには特徴と強みがあり、用途に応じた選択が重要です。
- 実用的な活用事例:ビジネス、クリエイティブ、教育・研究など様々な分野で、人間の能力を拡張するツールとして活用されています。
- 課題と展望:幻覚、バイアス、透明性、セキュリティなどの課題がある一方、特化型モデル、マルチモーダル能力強化、エッジAI、自律型エージェントなど、今後の発展が期待されています。
- Geminiの実体験:Googleのマルチモーダルモデルは、画像理解能力、検索連携、使いやすさなどの強みを持つ一方、専門分野の精度などに課題も見られました。
LLM技術は急速に進化を続けており、私たちの働き方や生活を大きく変えつつあります。
重要なのは、これらのツールを「人間の代替」ではなく「人間の能力を拡張するパートナー」として捉え、適切に活用することです。
AIの力を最大限に活かしながらも、人間ならではの創造性、倫理的判断、共感といった能力を組み合わせることで、より豊かで生産的な未来を築いていくことができるでしょう。
LLMの世界は日々進化しています。この記事が、その可能性を理解し活用するための第一歩となれば幸いです。
※本記事は2025年3月時点の情報に基づいています。AI技術の急速な進化により、記事公開後も新たな開発や変化が続いていることをご了承ください。

